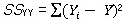Regresi
digunakan untuk menghitung perubahan efek yang tidak diketahui dari sebuah
variabel terhadap variabel lain, asumsi yang berlaku adalah terdapat hubungan
linier antar kedua variabel (X dan Y). Singkatnya regresi linier menghitung
seberapa besar perubahan Y ketika X berubah sebesar 1 unit.
Persamaan regresi dapat
ditulis sebagai berikut:
Y = β0 + β 1X1 +
β 2X2 + β 3X3 + β 4X4 +
…… + βnXn + e
Dimana:
Y = variabel dependen (tak bebas)
b0 = konstanta (tetapan)
X1, X2 =
variabel independen (bebas)
e = error
Ilustrasi:
Jika
kita memiliki data indeks gini selama 32 tahun sebagai variabel dependen,
dimana variabel independen yang kita perhitungkan antara lain adalah produk
domestik bruto (gdp), ekspor barang dan jasa (persentase dari gdp), indeks
harga konsumen (cpi), dan tingkat pengangguran yang merupakan persentase dari
total populasi penduduk (unem) Data diambil dari Badan Pusat Statistik (BPS)
dan World Bank. Kamu bisa ambil datanya disini >>>

Kali
ini kita akan melihat pengaruh variabel independen yang digunakan terhadap
indeks gini Indonesia selama 32 tahun (1979-2010). Software yang digunakan
adalah stata 12,
Tahap
impor data
Untuk
impor data tidak akan dijelaskan kembali disini, kamu bisa lihat di bahasan
statistik deskriptif *stata 12.
Setelah
masuk dalam file editor stata, kita lihat terlebih dahulu struktur datanya,

Dari
output kita lihat storage type tidak mengandung tipe string, data string harus
dirubah dulu agar dapat diolah dengan stata. Command diatas perlu kita buat
spesifik agar tidak memasukkan waktu (year) yang notabene merupakan integeer.

Kemudian
indikator statistik deskriptif yang menerangkan mean dan standar deviasi, bagi
yang belum memahami command dasar dalam stata bisa melihatnya di bahasa
statistik deskriptif *stata 12,

Berikutnya
kita akan masuk ke analisis regresi,

Command
robust disini dimaksudkan untuk
mengendalikan masalah heteroskedastisitas pada variabel, untuk kamu yang belum
memahami apa itu masalah heteroskedastisitas dalam regresi bisa lihat di
bahasan uji heteroskedastisitas dan multikolinearitas
Dari
regresi linier di atas dapat kita bangun model regresi dari nilai koefisien hasil regresi diatas sebagai berikut:
Y = β0 + β1X1 +
β2X2 + β3X3 + β4X4 +
… + βnXn + ε
gini = 0,3866975 +
0,00011406*gdp – 0,0021738*export + 0,001151*cpi – 0,0054169*unem + ε
- Nilai Prob > F sebesar 0,0174 masih lebih kecil daripada nilai kritik α=0,05 menunjukkan model signifikan secara statistik, hal ini juga mengindikasikan terdapatnya hubungan antara variabel Y dan X.
- R-squared menunjukkan keragaman Y yang dapat dijelaskan oleh model variabel X, artinya X dapat menjelaskan sebanyak 19,8 persen keragaman yang terdapat pada variabel Y.
- Nilai MSE menunjukkan standar deviasi/error dari model, semakin mendekati nol maka error semakin kecil, artinya model semakin baik.
- Nilai t diperoleh dari koefisien dibagi dengan robust standar error, nilainya harus lebih besar dari nilai t statistik pada selang kepercayaan 95% yaitu 1,96 (lihat tabel t), nilai yang paling dominan menjelaskan variabel gini adalah gdp sebesar 2,78.
- Nilai P > (t) merupakan nilai two-tail p-value, harus lebih kecil dari nilai kritik 0,05 atau 0,1. Dari hasil diatas variabel yang signifikan hanyalah gdp (0,010 < 0,05).
yang belum memahami konsep ANOVA bisa lihat di bahasan uji one way ANOVA.

Kemudian
kita akan melihat korelasi antar variabel dengan korelasi pearson, semakin
mendekati nilai 1, maka hubungan antar variabel akan semakin kuat,

Dari
output korelasi pearson kita dapat melihat hubungan yang paling signifikan
adalah yang ditandai dengan command star(0,05) yaitu gdp dengan unem sebesar 0,77 dan
cpi dengan export sebesar 0,73 dengan tingkat signifikansi 0,000 (0,05 > 0,000).
Kemudian
kita representasikan dengan grafik matriks korelasi dengan scatterplot untuk
melihat pola persebaran datanya secara keseluruhan,

Dari scatterplot di atas manakah menurut kamu yang memiliki pola
linier? Lihat antara gdp dengan cpi, kemudian export dengan cpi, gini dengan
cpi.
download materi versi pdf di bawah ini >>>
download link
download materi versi pdf di bawah ini >>>
download link